
Run large language models entirely on-device in Unreal Engine. Offline GGUF inference with token-by-token streaming, conversation context, and an editor model manager - with full Blueprint and C++ support.
Built on llama.cpp - load any GGUF model and run inference locally with no cloud services, no API keys, and no data leaving the device. Updated regularly to track upstream llama.cpp releases.
No internet connection, no API keys, no telemetry. All inference runs locally on the user's device.
Receive each generated token in real-time via delegates - update chat UIs and trigger gameplay events as the model writes.
Vulkan on Windows and Linux, Metal on Mac and iOS, CPU + intrinsics on Android and Meta Quest.
Browse, download, import, delete, and test models directly in project settings. Models ship with packaged builds automatically.
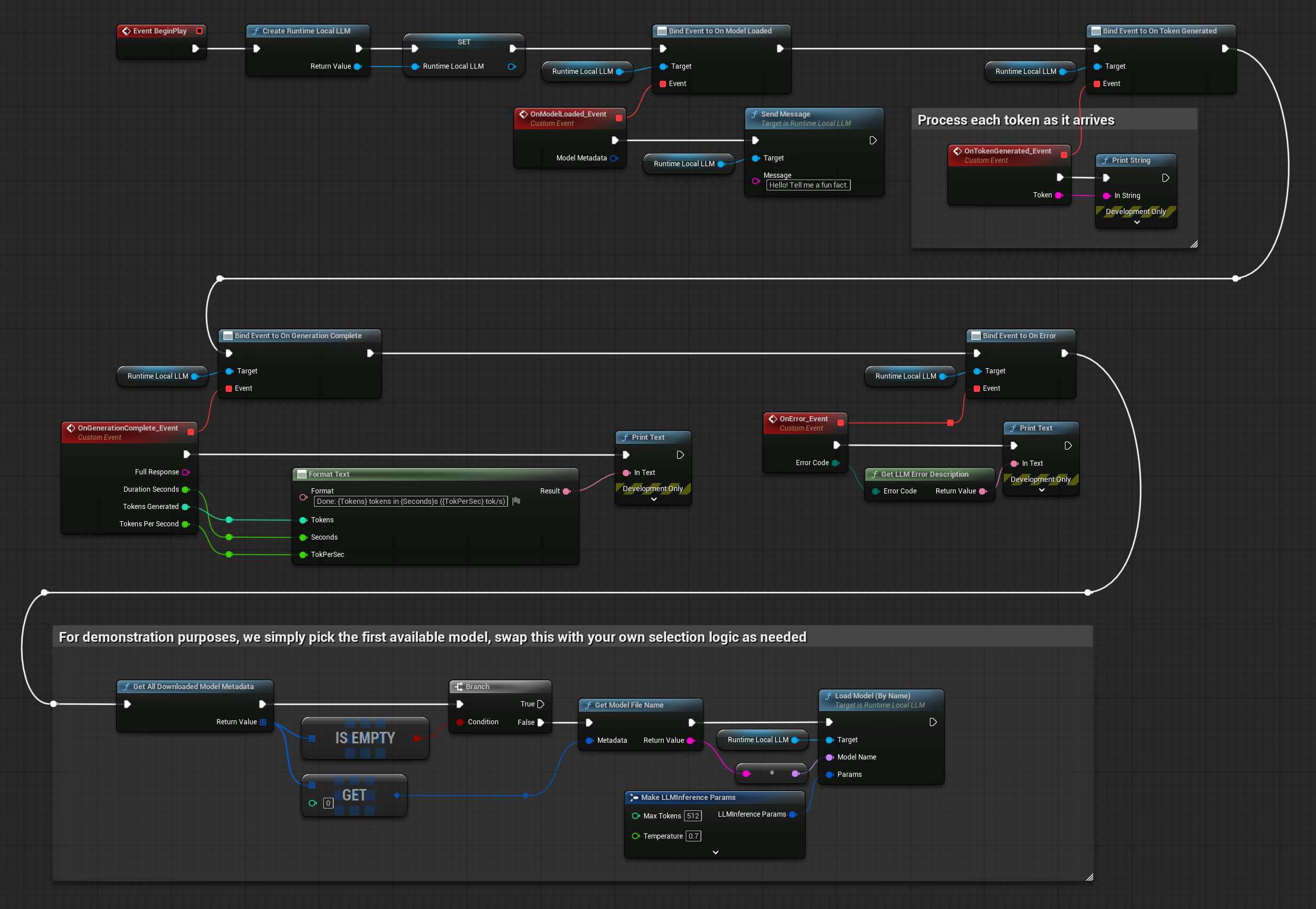
Manage models in the editor, load them at runtime with your chosen inference parameters, and send messages. Tokens stream back through delegates as the model generates - all on a background thread, with callbacks on the game thread.
Download from the catalog, import custom GGUF files, or fetch from URL at runtime
Choose by name, file path, or URL with configurable inference parameters
Pass user messages and receive streaming responses, with conversation context preserved
Drive NPC dialogue, generate dynamic content, or feed into other plugins like TTS and lip sync
Any model in GGUF format works. The editor includes a catalog of popular pre-defined models for one-click download, and you can import any custom GGUF file.
Llama (Meta), Mistral / Mixtral, Phi (Microsoft), Gemma (Google), Qwen (Alibaba), TinyLlama, and any other GGUF community model.
From Q2_K (smallest, fastest) through Q4_K_M, Q5_K_M, Q8_0, up to F16 / F32. Pick the level that fits your target device's RAM and performance budget.
The plugin is updated regularly on Fab to track upstream llama.cpp releases, so the latest GGUF model formats remain supported as they are released.
Hardware acceleration tuned per platform - GPU compute where available, CPU + intrinsics where not.
| Platform | Acceleration |
|---|---|
| Windows | Vulkan GPU |
| Linux | Vulkan GPU |
| Mac | Metal GPU |
| iOS | Metal GPU |
| Android | CPU + intrinsics |
| Meta Quest | CPU + intrinsics |
For mobile and VR devices, smaller quantizations (Q2_K through Q4_K_M) with compact models (1B–3B parameters) are recommended. Desktop platforms can run larger models with higher quantization levels.
A dedicated settings panel inside the Unreal Editor for browsing, downloading, importing, deleting, and testing models - no command-line tools or external downloads required.
Browse a built-in catalog of popular models with one-click download. Multiple downloads in parallel, with progress bars and cancel support.
Import any GGUF file from disk or a direct URL. Custom models are treated identically to catalog models and ship with packaged builds.
A built-in test window lets you select a model, configure parameters, send prompts, and watch responses stream in real-time - all without entering Play mode.
Beyond basic loading and inference, the plugin provides multiple model loading methods, async Blueprint nodes, runtime downloading, conversation context management, and configurable inference parameters.
Load by model name, by absolute file path, or directly from a URL with automatic download. Pre-cache models without loading.
Each generated token fires a delegate on the game thread - immediately update chat UIs, trigger gameplay events, or pipe output into other systems as it arrives.
Multi-turn conversations preserve message history automatically. Reset context at any time, optionally keeping the system prompt for persistent character behavior.
Control temperature, Top-P, Top-K, repeat penalty, GPU layer offload, context size, seed, thread count, max tokens, and system prompt - per model load.
Dedicated async nodes for loading, sending messages, and downloading - with output pins for tokens, completion, progress, and errors. No manual delegate binding needed.
Models in Content/RuntimeLocalLLM/Models are auto-staged via NonUFS so they ship with packaged builds. No manual project config required.
Blueprint Example - Simple chat with streaming responses
A Windows demo is available so you can experience on-device inference firsthand. The demo includes a chat interface with streaming responses, runtime model downloads via URL, and a settings menu for inference parameters - all built with Blueprints and UMG.
Send messages and watch responses generate token by token in real-time
Models ready out of the box, plus runtime URL downloads for additional models
In-game settings menu for temperature, max tokens, context size, and more
Full Blueprint implementation in the plugin's Demo content folder, supporting UE 4.27+
Video Tutorial
Demo Project Preview
A few of the workflows the plugin supports out of the box - all running locally with no external dependencies.
Character-driven conversations with persistent context - NPCs remember past exchanges and stay in character via the system prompt.
Generate quest text, item descriptions, lore snippets, or barks at runtime - varying output per session without authoring every variant.
In-game assistants and chatbots that work without internet - useful for offline games, air-gapped deployments, and privacy-sensitive applications.
Pair with Speech Recognizer for voice input, TTS for spoken responses, and Lip Sync for animation - building fully offline conversational characters.
Runtime Local LLM is the offline AI brain of the Georgy Dev plugin suite - combine it with speech recognition, TTS, and lip sync for fully on-device conversational characters.
Process and play TTS audio output at runtime. Essential companion for handling streaming audio data from any TTS provider.
Learn moreOffline speech-to-text via Whisper. Convert player speech to text and feed it directly into the local LLM.
Learn moreOffline TTS with 2800+ voices across 51 languages - speak the LLM's responses out loud locally.
Learn moreReal-time lip sync for MetaHumans and custom characters, driven by the audio output of synthesized LLM responses.
Learn moreCloud AI alternative - OpenAI, Claude, DeepSeek, and others. Use alongside Runtime Local LLM for hybrid online/offline scenarios.
Learn moreComprehensive documentation covers the editor model manager, runtime API, inference parameters, ready-to-use examples (simple chat, NPC dialogue, pre-downloading), and the bundled demo project.
Step-by-step guides for all features, with Blueprint and C++ examples
Active Discord community with developer support
Tailored integration or feature development - [email protected]
Editor - Importing custom GGUF models
Available on Fab for UE 4.27 – 5.8. Includes the editor model manager, runtime API, demo project, and full documentation.