
Cross-platform, offline text-to-speech synthesis for Unreal Engine. Generate natural-sounding speech with 2800+ voices across 51 languages - including Kokoro studio-quality voice models and streaming TTS - with full Blueprint and C++ support.
Text is synthesized entirely on-device using Piper or Kokoro voice models via ONNX Runtime - standard or streaming - with no internet connection, no API keys, and no data sent externally. The resulting PCM audio integrates directly with Runtime Audio Importer for immediate playback.
Any string from Blueprint, C++, or piped in from an AI chatbot response
Select a Piper or Kokoro model by name or object, with optional speaker and quality settings
ONNX Runtime processes the text locally - standard or streaming - with no data sent externally
Float32 PCM data ready for playback, saving, lip sync, or any downstream audio processing
Two model architectures covering a wide range of use cases, from broad language coverage to studio-quality output.
ONNX-based models covering 51 languages with 166 voice models and 2800+ unique speakers. Accepts custom-trained ONNX models.
151 high-quality open-source voice models across 8 languages: English (US & UK), Simplified Chinese, Spanish, Portuguese, Hindi, French, and Italian. Among the highest-quality open-source TTS solutions available.
Import your own Piper (ONNX + JSON) or Kokoro (BIN + JSON) voice models directly via the plugin settings for specialized voices or languages.
Broad language coverage and first-class support for every major platform Unreal Engine targets.
Beyond basic synthesis, the plugin provides streaming output, multi-speaker selection, cancellable operations, and model management utilities - all accessible from Blueprints or C++.
Two synthesis modes: complete the full text before returning audio, or stream PCM chunks in real-time as they're generated for immediate playback of long texts.
Many models support multiple speakers - English LibriTTS includes 900+ distinct voices. Query speaker count per model and select by index at synthesis time.
Cancel any ongoing synthesis at any time - essential for responsive applications that need to interrupt and restart speech mid-generation.
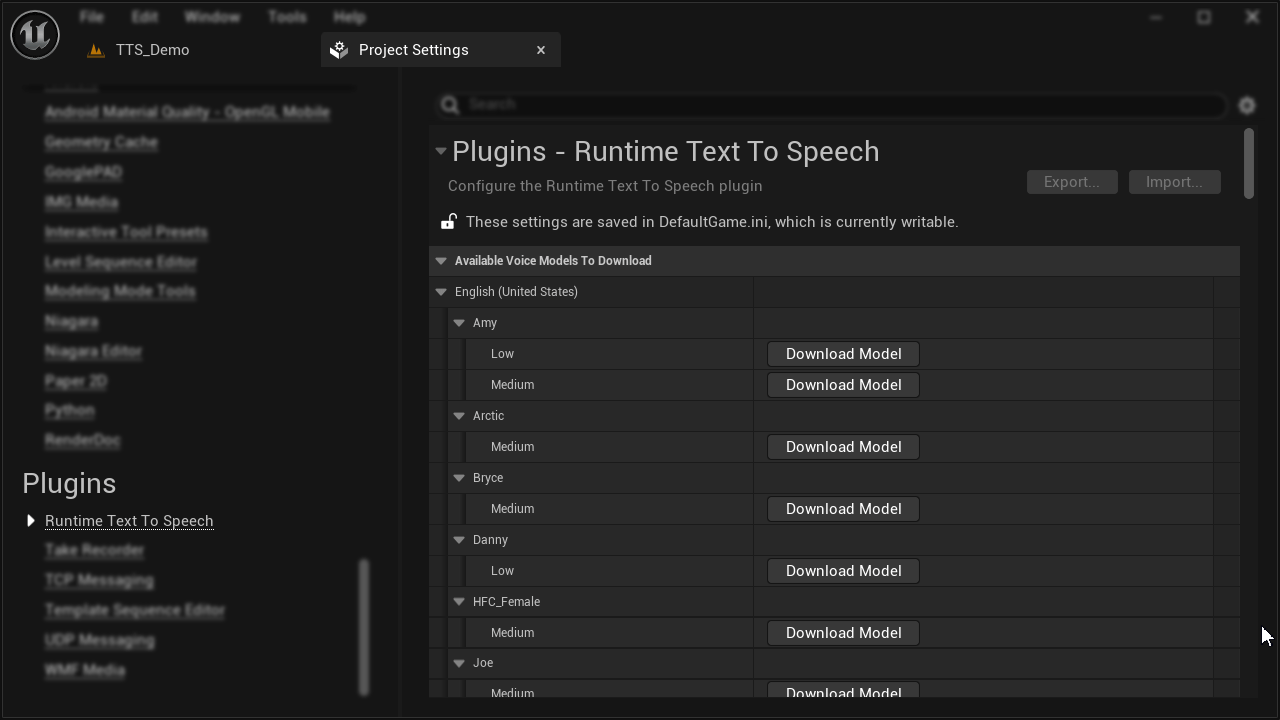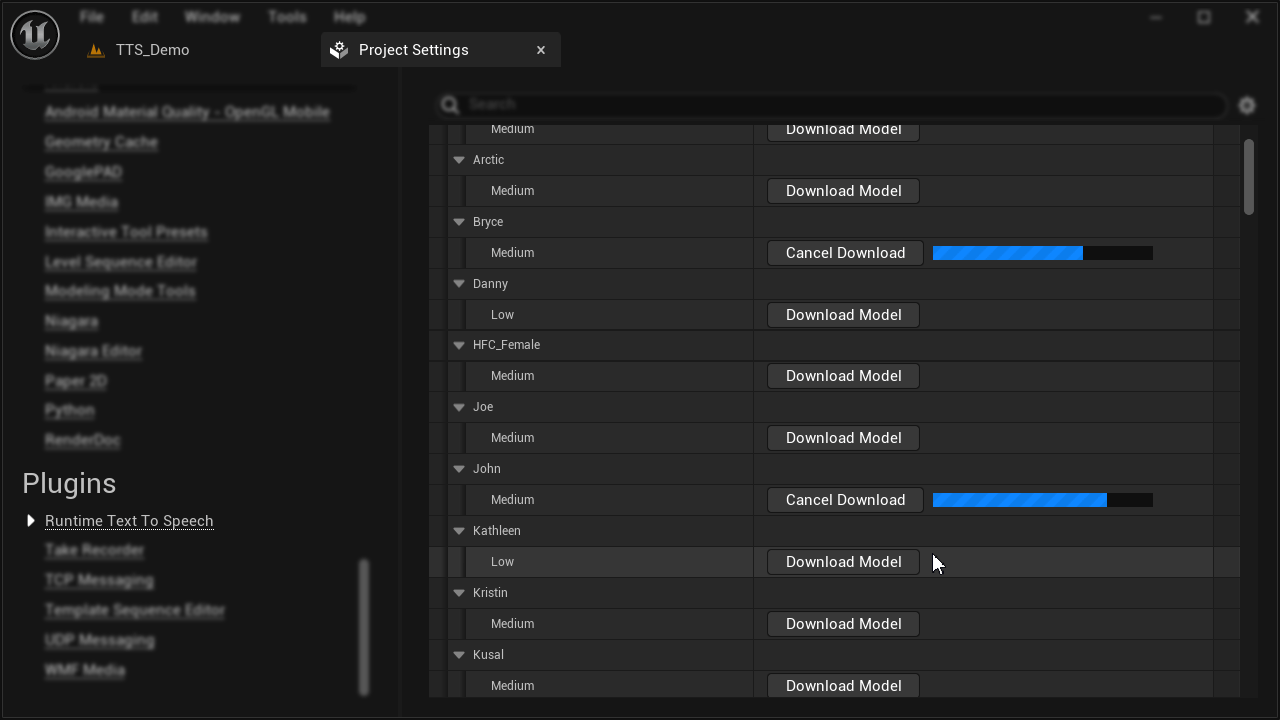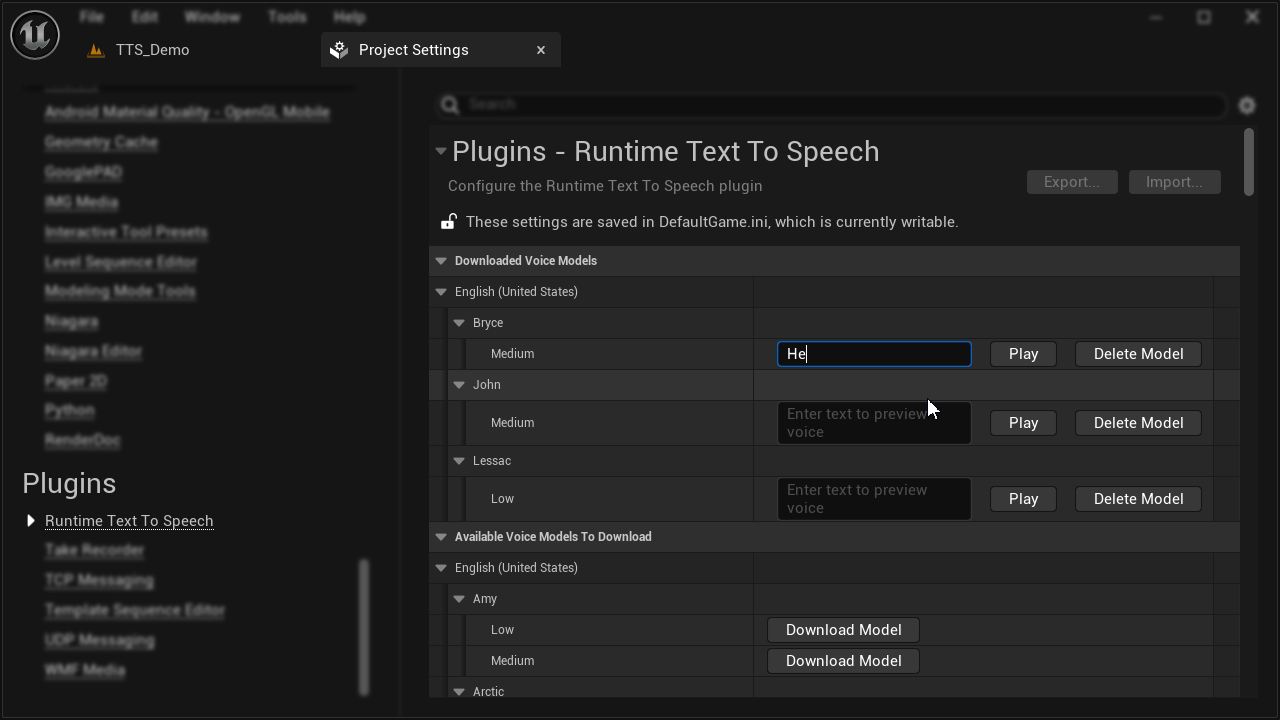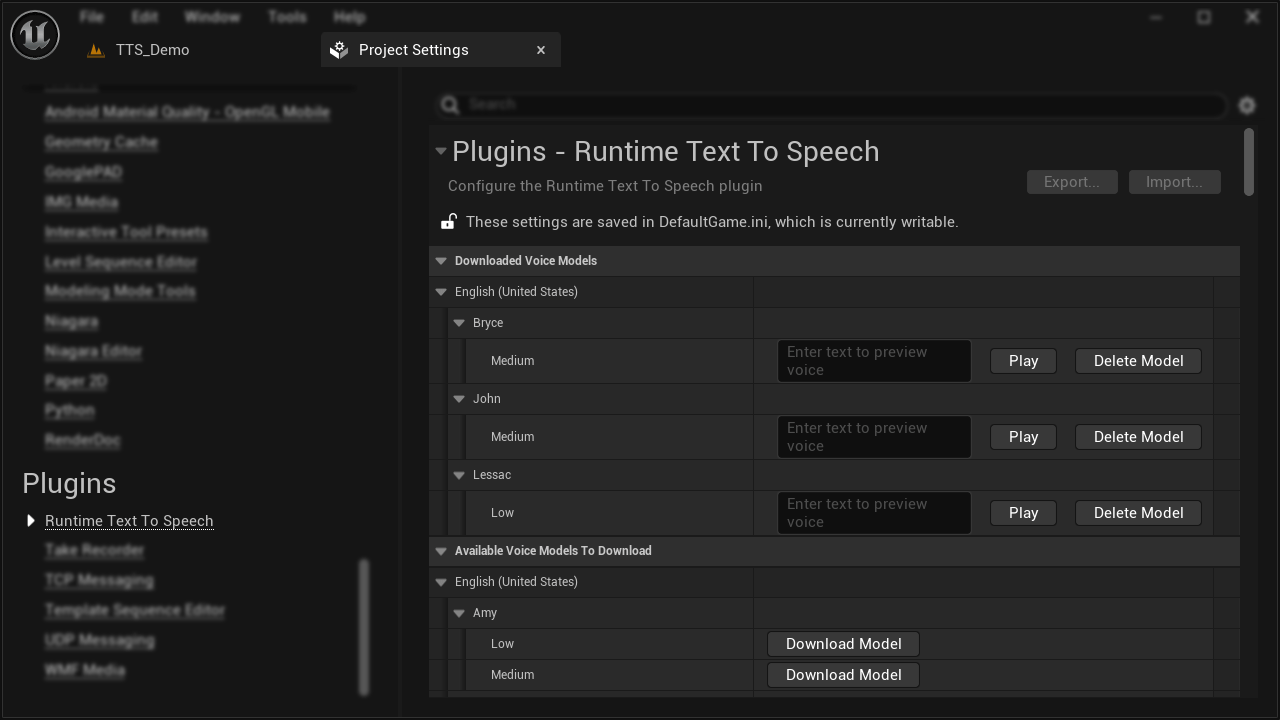
Download, preview, and manage voice models directly from the Unreal Editor. List available models, query metadata, and control storage without leaving the engine.
Retrieve model metadata, language, quality tier, and speaker count by name or object reference. Select models dynamically at runtime based on language or other criteria.
No internet connection, no API keys, no data leaving the device. Suitable for privacy-sensitive applications, air-gapped environments, and offline games.
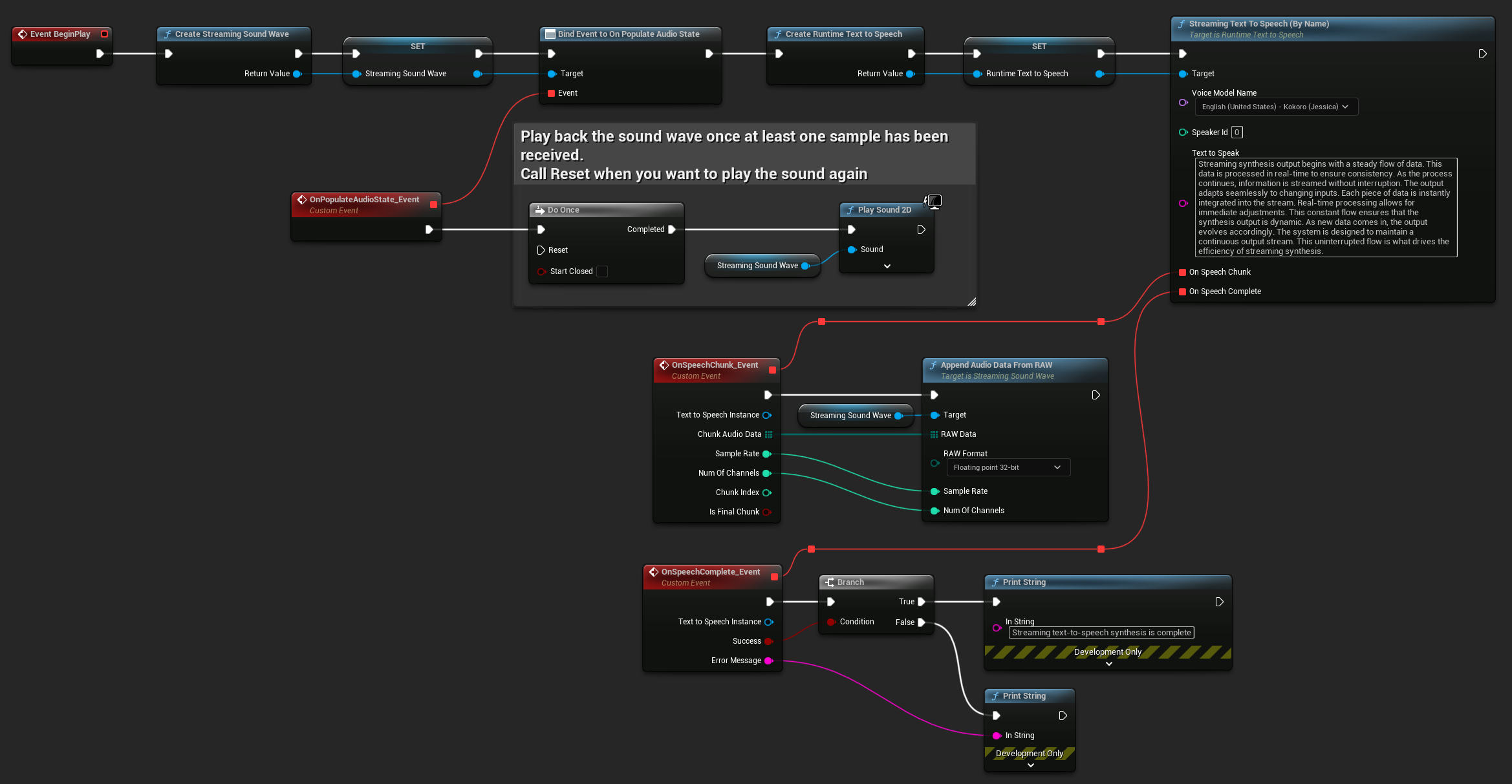
Blueprint Example - Streaming TTS with real-time playback
A Windows demo is available to experience the plugin's voice quality firsthand. The demo includes a curated selection of Piper and Kokoro voice models showcasing different languages, speaker counts, and synthesis modes.
Standard, multi-speaker, and Kokoro studio-quality models
Compare both synthesis modes side by side with custom text input
Full Blueprint implementation in the demo project for reference
Video Tutorial
Runtime Text To Speech is the voice output layer of the Georgy Dev plugin suite - driving lip sync, powering AI character pipelines, and completing the speech recognition loop.
Receive PCM audio output from TTS synthesis and play it back, stream it, or process it further at runtime.
Learn moreDrive real-time lip sync animations on MetaHuman and custom characters directly from TTS audio output.
Learn moreClose the voice loop - pair offline speech recognition with offline TTS for fully on-device conversational experiences.
Learn morePipe AI-generated text from various providers directly into TTS synthesis for fully voiced NPC responses.
Learn moreGenerate dialogue with on-device LLMs offline, then drive lip sync from the synthesized speech for fully offline character interactions.
Learn moreComprehensive documentation covers all synthesis modes, model management, multi-speaker configuration, streaming workflows, and platform-specific guidance.
Step-by-step guides for all features, with Blueprint and C++ examples
Active Discord community with developer support
Tailored integration or feature development - [email protected]
Demo - Voice model download and preview in the editor
Available on Fab for UE 4.27 – 5.8. Includes all voice models, full documentation, and a demo project showcasing streaming TTS and Kokoro voices.